
My main question is about /run/user/1000:
- Should I avoid touching it?
- Could I delete it?
- Is there something wrong with it?
Background: I’m fairly new to Linux and just getting used to it.
I use fsearch to quickly find files (because my filenaming convention helps me to get nearly everything in mere seconds). Yesterday I decided to let it index from root and lower instead of just my home folder.
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud ‘drive’ is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
Searching: Looking for answers I read these, but couldnt make sense of it.
- https://unix.stackexchange.com/questions/162900/what-is-this-folder-run-user-1000
- https://forums.linuxmint.com/viewtopic.php?t=412850 So if its a bug with flatpaks I’m inclined to delete a certain db at ~/.local/share/flatpak/db
Puzzled:
- Is this folder some RAM drive so my disk doesnt show anything strange? Because this folder doesnt even show up at the root level.
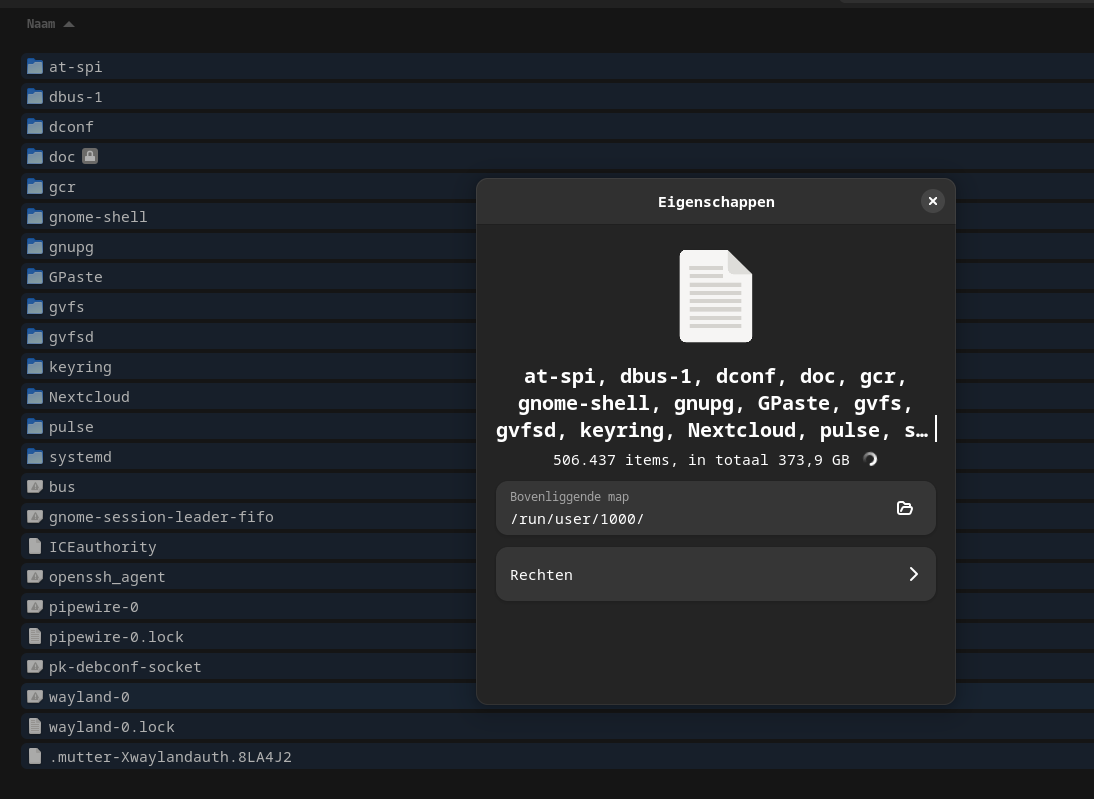
- Are these even real? Because the size of it (aprox 370 GB) is even bigger then my disksize (screenshot).
Any tips about course of (in)action appreciated.
You must log in or # to comment.
/run contains all sorts of virtual stuff, it doesn’t persist over a reboot,
I would advise against deleting anything in it as those files are used by programs running as whether user has the ID of 1000 (most likely you)
it contains things such as sockets and lock files so that programs can interact with each other
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud ‘drive’ is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
In Linux a file can show up several times in the filesystem without being duplicated. Symbolic links and hard links will cause this to happen, and they’re a normal part of organizing the filesystem. Just because you see a file in several places, that doesn’t mean disk space is wasted with duplicates. There may be only one physical copy of the file, appearing in multiple places. With hard links you need to be especially careful about deleting, since you’ll think you’re deleting one of several duplicates but you’ll in fact delete the only copy of the file.
Don’t delete it. It’s an area of the filesystem where the current user session data is kept. This includes things like sockets to communicate with other session components and lock files. It’s usually hosted on a ram disk so takes up no space in the system and goes away when you shutdown your machine.
Or it comes back the same way but doesn’t pose a problem either?
You’re going to want to look up things like symlinks, hard links, fuse filesystems, and bind mounts among other concepts. Your “whole directory” and other duplicates are artifacts of how the filesystem and process management works, and simply running fsearch or find over them is going to be confusing if you don’t know what you’re looking at.
One Unix concept that carries over to Linux is that everything is a file. Your shared memory space, process data, device driver interfaces, etc, all of it is accessible somewhere in the same virtual filesystem tree as the actual files.
Because of this, there’s very little reason to have the whole filesystem indexed from root. If you’re worried about space usage, you want to work with packages through the package manager. If you’re worried about system integrity, you’ll want package validators.
Thanks, gives me direction in which way to do research.
Thanks everybody, I learned a ton these 2 days. Like a ’ jump’ in understanding. Not only the specific answer to my concrete question but also on a conceptual level as well.
The thing that makes Linux next level for me now is the extra ‘abstraction layer’.
Thing is, for me, digital files always were as tangible as the analog object they represent. A digital document is as ‘real’ as a paper document. An email as real as a letter. But untill now files where ‘real’ digital artefacts. And thats … a bit different with ‘virtual’ files, sort of.
Anyway, new concepts to explore which is great!
I think others have answered what the folder should do.
FSearch is great, but I wouldn’t index the entire file system. There isn’t much point in indexing things you won’t be using such as all the system files and the representations of hardware processes. It’s a bit like on Windows indexing c:\windows - you just don’t need all that clogging up your search results. But the Linux filesystem encompasses much more so you’d get even more stuff.
On my system I index my home folder (where all your own files will be kept) and my mount points (for me a series of drives I mount under /mnt/). You could also index /media (or variants) as that is where USB drives, and CDs etc would mount to - but I don’t tend to index USB sticks etc.
I can see circumstances where you might want to index other locations depending on how you use fsearch and Linux, but I think for most users it’d just be unnecessary indexing and results.
Edit: I saw someone else mention /etc too. That can be useful if you want to find system config files. They also mentioned /usr/share/docs which contains a lot of the Linux manual/distro docs amongst others. If you want to access that then it’s not a bad idea to index it, although most people are online all the time now on multiple devices so it may be a bit redundant for most users day to day; I tend to just search online documentation.

{kind=link}